What is speaker diarization?
In simple terms, diarization automatically partitions an audio recording into segments corresponding to different speakers. This is done by analyzing the audio signal and using various techniques to differentiate between different speakers based on their individual voice characteristics.
The result is a transcript split into different sections, each corresponding to a different speaker.
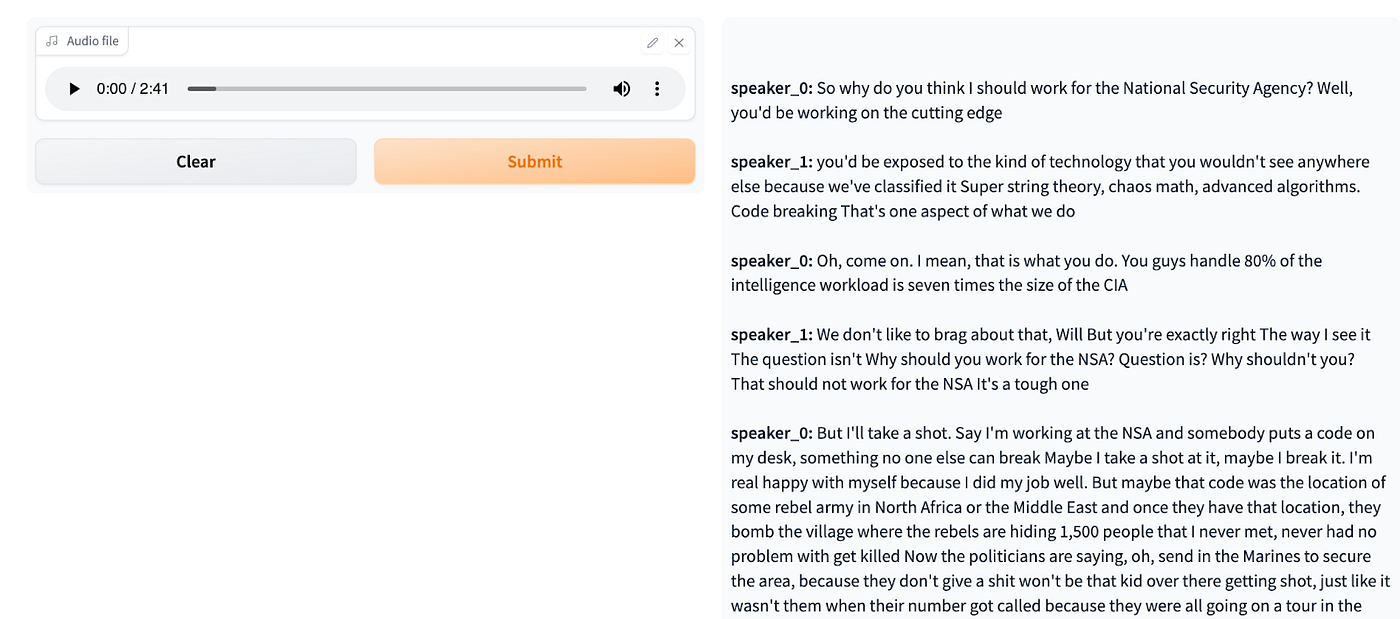
Example of a speaker-based transcript.
Activating the diarization
Gladia's API is simple, and as with most of the other API options, you can toggle the diarization using the "toggle_diarization" option to "true".
Channel-based diarization doesn't require activating diarization
Using CURL
curl --request POST \
--url 'https://api.gladia.io/audio/text/audio-transcription/?model=large-v2' \
--header 'accept: application/json' \
--header 'x-gladia-key: XXXXXXXXXXX' \
--header 'content-type: multipart/form-data' \
--form audio_url=http://files.gladia.io/example/audio-transcription/split_infinity.wav \
--form toggle_diarization=true \
--form diarization_max_speakers=2 \
--form output_format=json
Using any programming language
Please visit the interactive documentation to generate your favorite language snippet:
https://docs.gladia.io/reference/recognize_audio_text_audio_transcription__post
Using the CLI
gladia --audio-url http://files.gladia.io/example/audio-transcription/split_infinity.wav \
--diarization #this will activate the diarization
--diarization-max-speakers 2 #define the estimated maximum number of speakers in the audio
Interpreting the results
Mechanical diarization (1 speaker per channel)
Read the "channel" key in the output.
{
"prediction": [
{
"time_begin": 0.09,
"time_end": 2.07,
"transcription": "Split infinity",
"language": "en",
"confidence": 0.55,
"words": [
{
"word": " Split",
"begin": 0,
"end": 0.66,
"confidence": 0.7
},
{
"word": " infinity",
"begin": 0.66,
"end": 1.38,
"confidence": 0.4
}
],
"speaker": "not_activated",
"channel": "channel_0"
},
{...}
]
}
channel_0 will represent speaker 1 and channel_1 represents speaker 2.
channel based diarization doesn't require activating diarization
Algorithm-based diarization (multiple speakers per channel)
Read the "speaker" key in the output.
{
"prediction": [
{
"time_begin": 2.13,
"time_end": 4.13,
"transcription": "in a time when less is more",
"language": "en",
"confidence": 0.65,
"words": [
{
"word": " in",
"begin": 0,
"end": 0.52,
"confidence": 0.59
},
{
"word": " a",
"begin": 0.52,
"end": 0.74,
"confidence": 0.99
},
{
"word": " time",
"begin": 0.74,
"end": 1.2,
"confidence": 0.82
},
{
"word": " when",
"begin": 1.2,
"end": 1.66,
"confidence": 0.86
},
{
"word": " less",
"begin": 1.66,
"end": 1.94,
"confidence": 0.87
},
{
"word": " is",
"begin": 1.94,
"end": 2.28,
"confidence": 0.91
},
{
"word": " more.",
"begin": 2.28,
"end": 2.56,
"confidence": 0.88
}
],
"speaker": "speaker_1",
"channel": "channel_0"
},{...}
]
}
In this case, the speaker's case can be extracted directly from the "speaker" key.
More About Diarization
The key complexity of diarization is that input audio comes in many shapes and sizes. Audio files essentially consist of channels, with the following classification used to distinguish between the different types:
- Mono (single channel), i.e. a track
- Stereo (dual-channel), i.e. two tracks
- Multi-channel, i.e. several tracks
One of the main challenges in AI transcription has been to make diarization work with all kinds of audio. This task is more tricky than it may appear initially, given that stereo and multi-channel audio can contain duplicate signals, doubling channels and leading to repetitions in the final transcript.
When building our API, our goal was to make sure it could process all kinds of files without compromising the quality and speed of transcription.
When it comes to diarization, we rely on two main approaches:
Mechanical split diarization is most suitable for telecom & call center use cases.
The speaker separation, in this case, is mechanical because each speaker corresponds to a unique channel (left channel — person 1, right — person 2).
AI-based (footprinting) split diarization is suitable for other use cases.
It is based on Gladia’s proprietary algorithm and is suitable for use cases like multi-speaker virtual meetings, video content, and podcasts, where a single channel can contain multiple speakers and the input files are prone to duplicate signals.
As part of our proprietary AI-based diarization, we developed a method to avoid transcript repetitions by seamlessly detecting unique vs. duplicate channels based on similarity.
The API will automatically pick the proper diarization method for your audio file and produce a high-quality speaker-based transcript — without sacrificing the unmatched transcription speed (under 60s per hour of audio).
Speaker diarization is a broad subject in speech recognition. You can check out this blog post for more detailed information around the subject.
How to know which diarization I need to use
Open Audacity or any other audio editing software, drag and drop your audio or video file on the Audacity interface and check if the two channels are similar.
Profile of multiple speakers per channel file
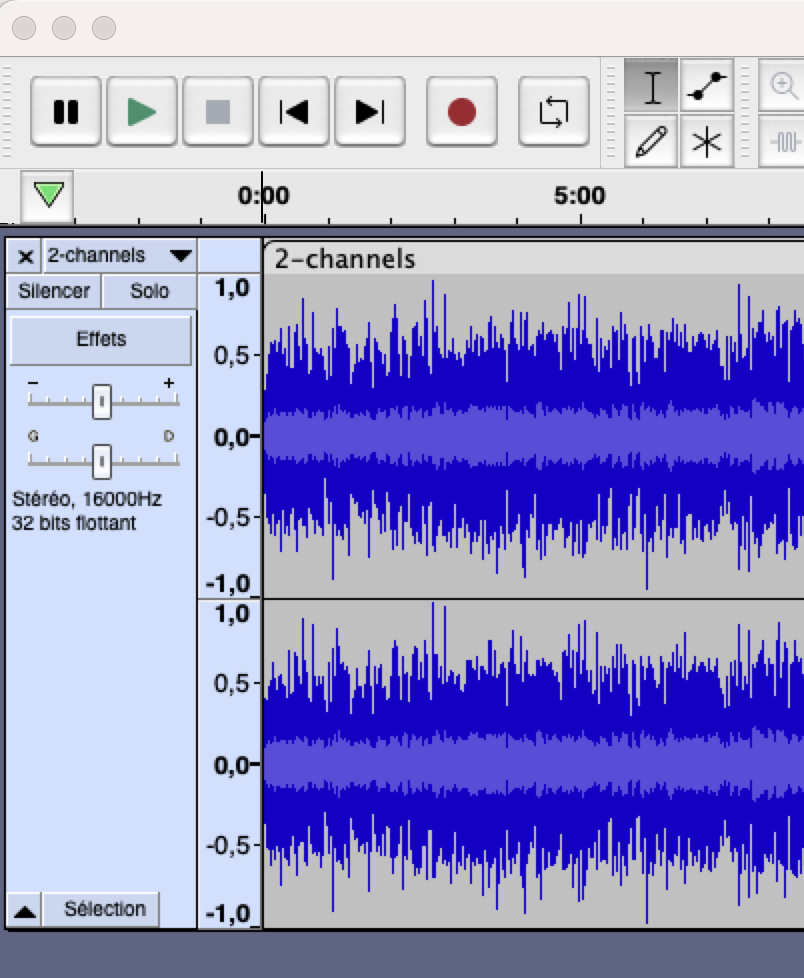
2 similar channels with similar profile
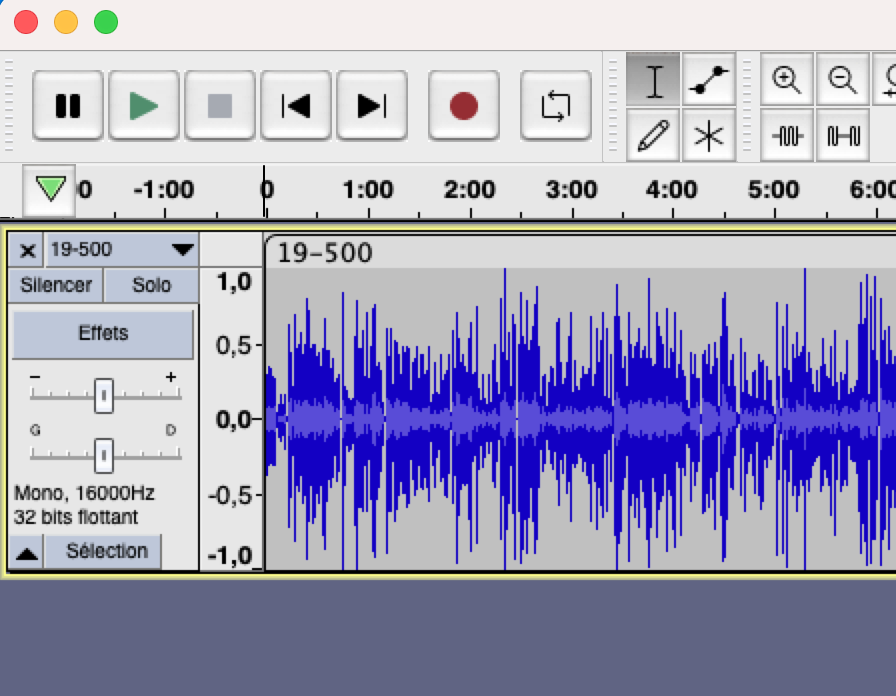
1 channel with multiple speakers
Profil of a one-speaker-per-channel audio file
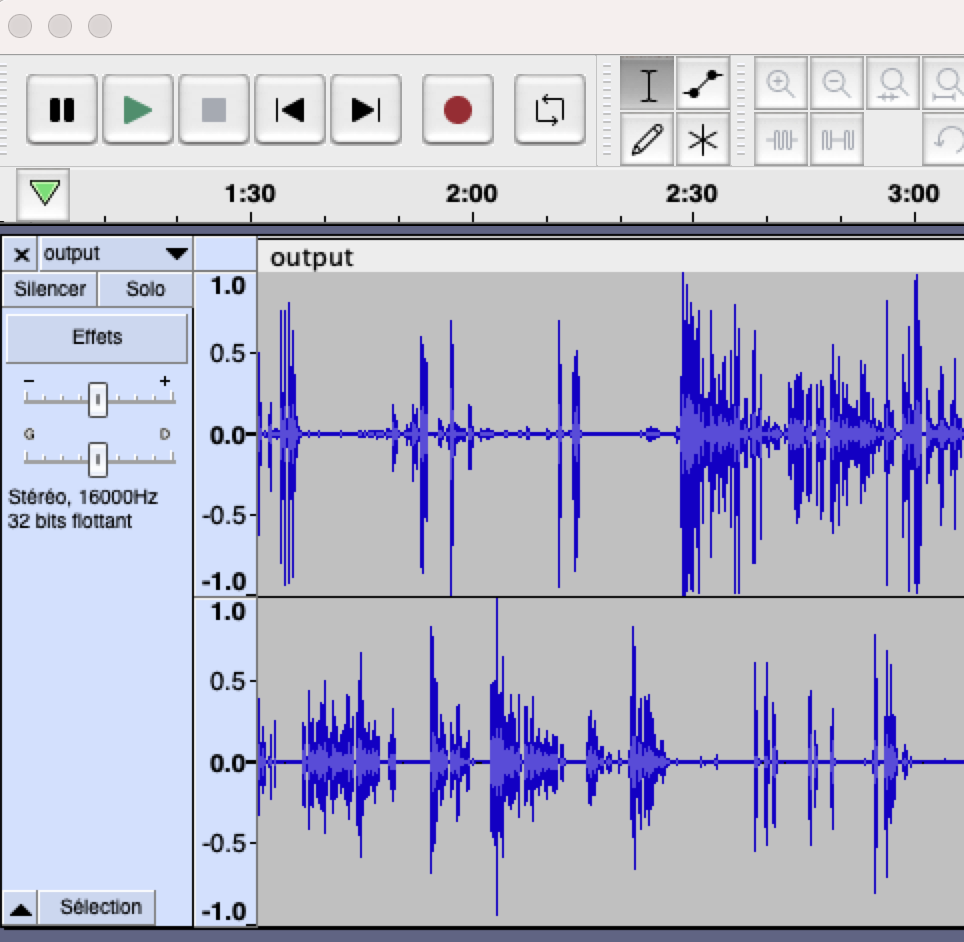
2 channels with 1 speaker per channel
As we can see here, the conversation with back and forth is pretty apparent, and the timestamp of each channel will give a good diarization with a low risk of audio overlapping, resulting in better recognition and performance, and no diarization error.